
資料如何被表達與組織、如何被查詢?
資料的結構往往依應用程式而定,當我們要儲存這些資料結構時,可以用 資料模型 (Data Model) 來表示它們。用於資料儲存的通用資料模型有:
- 關聯模型 (Relational Model):以表 (table) 的形式表示。
- 文件模型 (Document Model):以 JSON / XML 文件 (document) 的形式表示。
- 圖模型 (Graph Model):以圖 (graph) 的形式表示。
換句話說,資料模型是應用程式開發者提供給資料庫的資料格式,它會深深影響上層的軟體,所以選擇一個能與應用程式契合的資料模型相當重要。
從歷史上看,關聯模型是最早出現的。之後,非關聯式儲存 NoSQL (Not Only SQL) 才興起並分化為文件資料庫 (Document Database) 和圖形資料庫 (Graph Database) 兩個主要方向。
採用 NoSQL 資料庫的原因,通常包括需要比關聯式 DB 更容易實現的擴展性(比如支援超大型 dataset 或超高的寫入吞吐量),以及大家對免費和開源軟體的偏好等。
Relational Model#
由 SQL 所奠基的模型,資料以 table 和 row 組成,在資料儲存領域有不朽的地位。
如果用 relational schema 呈現 Ally 的履歷,依最傳統 正規化 的方式來表示,會將 user 資訊、教育程度、工作經歷分別存在各自的 table,並透過 foreign key 來參照彼此的關聯。
user table
| user_id | first_name | last_name |
|---|---|---|
| 100 | Ally | W |
education table
| id | user_id | school | start | end |
|---|---|---|---|---|
| 807 | 100 | Harvard | 2016 | 2018 |
| 806 | 100 | Oxford | 2013 | 2015 |
position table
| id | user_id | org | title |
|---|---|---|---|
| 459 | 100 | engineer | |
| 458 | 100 | Amazon | engineer |
資料庫正規化的中心思想在於「消除重複」。
根據經驗法則,如果有一個資訊只需要存在一個地方,卻被複製幾份到多處,這樣的 schema 就是未經正規化的。
關聯模型搭配 SQL 操作,是一種宣告式 (declarative) 查詢語言,採用類似英文句子的語法,查詢者只需要宣告「想要什麼結果」,至於用哪個索引、先掃哪張表等執行細節,資料庫會自己最佳化。常見的資料庫有 MySQL, PostgreSQL, SQL Server, Oracle 等。模型主要的優勢在於支援 join 操作,以及能表達一對多 (one-to-many)、多對多 (many-to-many) 的關係。
宣告式查詢語言能「抽象化」資料的操作,隱藏 DB 引擎的實作細節,讓系統更有彈性;也就是 DB 系統可以在不改變原始 query 語句的情況下,對底層的性能做改進。
Document Model#
模型將資料表示為 key-value 的樣貌,常見 use case 為當資料是 self-contained document,以及 document 彼此之間的關聯性較小時。
如果以 JSON document 呈現 Ally 的履歷,所有資料會被攤開在單一文件中。這邊的資料有一對多的關係,代表資料在邏輯上存在樹狀結構 。
{
"user_id": 100,
"first_name": "Ally",
"last_name": "W",
"education": [
{"school": "Harvard", "start": 2016, "end": 2018},
{"school": "Oxford", "start": 2013, "end": 2015}
],
"position": [
{"org": "Google", "title": "engineer"},
{"org": "Amazon", "tible": "engineer"}
]
}
文件模型通常搭配 JSON-based 的查詢語法,以 MongoDB 的 Aggregation Pipeline 為例,查詢者用一個 pipeline 串接多個資料轉換步驟 (stage),並且決定執行順序;其中每個 stage 本身採用宣告式的描述,整體查詢機制像是介於宣告式與命令式之間。模型的主要優勢包括 schema 彈性,也就是文件的結構可以隨著時間或不同需求而自由變化;以及 局部性 (locality) 所帶來的效能,由於相關資料通常儲存在同一文件或相近位置,使得讀取單一實體 (比如 Ally 這個人) 時的存取速度非常快。
MapReduce 是一種用於跨多台機器處理大量資料的程式設計模型 (programming model)。
部分 NoSQL 資料庫(比如 MongoDB)有支援 MapReduce,作為跨機器唯讀查詢 (read-only query) 的機制。
相較之下 MapReduce 更偏向命令式 (imperative) 查詢,查詢者必須自己定義「如何處理資料」與一步一步要執行的流程。
Graph Model#
模型用 頂點 與 邊 來描述資料及其關係,適合表示高度互相連結、關係複雜的資料。
use case 為當任何資料之間都存在互相關聯的可能時,圖模型最為適用。
- 頂點 (vertex / node / entity): 資料中的實體,比如一個人、一個地點、或一件物品。
- 邊 (edge / relationship / arc): 頂點之間的關係或關聯性。
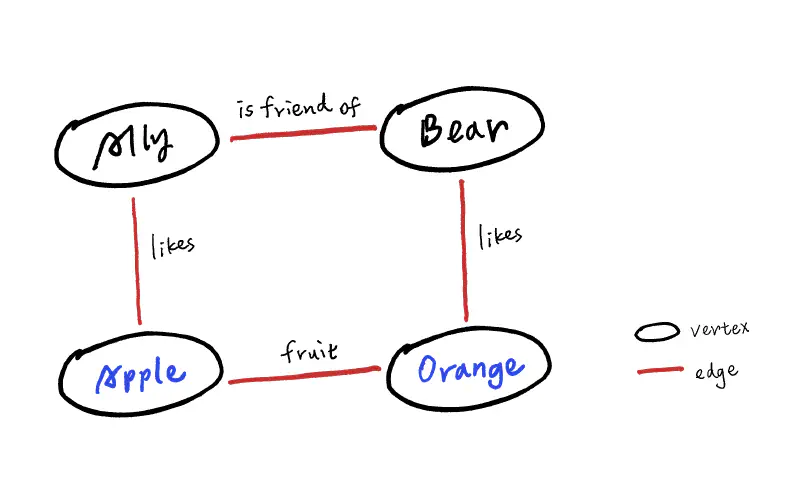
圖模型的優勢在於能高效地遍歷 (traverse) 圖形,快速解析大量節點之間的關聯,並且沒有 schema 限制哪些事物能被關聯,單一 graph 就能儲存不同種類的資訊。這些特性給了資料建模很大的靈活性,比如不同顆粒度的資料可以同時展示:Bear 現居紐約 (城市) 並出生於法國 (國家)。
可以用 graph 來建模的資料像是社交網路、網頁的連接結構圖、道路網絡、知識圖譜(Knowledge Graph),而一些演算法可以操作這些 graph,比如汽車導航尋找兩地點之間的最短路徑、PageRank 計算網頁的熱門程度來排名。
常用的 graph model 有「屬性圖」(Property Graph):比如 Neo4j 資料庫,搭配 Cypher 查詢;以及「三元儲存」(Triple Store):比如 AllegroGraph 資料庫,搭配 SPARQL 查詢。SQL 也可以查詢 graph 只是比較笨拙。
# cypher: 找出跟 a 有 3~5 層追蹤關係的所有使用者
MATCH (a:User)-[:FOLLOWS*3..5]->(b)
RETURN b
從 Data Model 角度比較不同 Database#
資料庫的差異可以從資料模型、容錯性、並行處理等方面來比較,這裡從資料模型角度來看:
- 哪種模型讓應用程式的 code 更簡潔
這取決於資料 item 之間的關係:
| 資料特性 | 適合的模型 | 說明 |
|---|---|---|
| document-like 結構 | document model | 當資料有一對多關係的樹狀結構、或資料之間彼此獨立或關聯性不高,程式碼可以很直接的處理 self-contained 的資料。 |
| 有關聯、簡單多對多關係 | relational model | 當資料彼此有關聯,模型能勝任簡單的多對多關係,透過 join 和 foreign key 保持結構化。 |
| 高度複雜的關聯性 | graph model | 隨著資料間關聯性越複雜,用圖模型來表達最自然。程式碼能以遍歷關係的方式來查詢,避免關聯模型的 join 或文件模型的複雜巢狀結構。 |
- schema 的靈活性
schema 指的是資料的結構定義,包括欄位有哪些、類型是什麼、哪些必填、哪些可選。不同資料庫處理 schema 的方式不同,要考慮資料是否穩定、query 複雜度、團隊狀況等等來決定 schema 的使用方式。
| 資料庫 | schema 處理方式 | 說明 | 特性 |
|---|---|---|---|
| relational database | schema-on-write (寫入時套用) | 資料結構是顯式的。DB 會確保所有寫入的資料都符合 schema 規範,不符合就寫不進去。 | 資料結構固定,帶來強一致性、適合複雜 query。但當 schema 要更動時比較麻煩,較難適應快速變化的資料結構。 |
| document database | schema-on-read (讀取時套用) | 資料的結構是隱式的,在讀取資料時才會被詮釋。也就是資料寫進 DB 時不檢查結構,在讀取時才由應用程式的程式碼定義、檢查和轉換。 | 資料先存再說,開發快又有彈性,應用程式比較能適應快速變化的需求。但多人協作時不容易維持一致格式,而且資料結構不一致可能使查詢變困難,大規模分析時需要先清理資料,ETL 成本高。 |
| graph database | 大多是 schema-flexible,通常採用 schema-on-read 風格 | 寫入資料時可以不定義 schema。query 在讀取時依現有的 node、edge、property 結構來解讀。 | 由於 DB 的核心結構 (node / edge / property) 本身就是資料的一部分,schema 已經隱含在資料中,靈活性很高。 |
- 查詢資料時的局部性
局部性指的是一個 query 是否能在同一份資料區塊中取得所有需要的資料。這邊討論空間上的儲存局部性,如果資料在物理位置上很接近,一個 query 可以一次把需要的資料讀進記憶體,就代表有好的局部性,效能會比較好。
當應用程式需要頻繁的存取整份文件 (比如 render 在網頁上),document model 的儲存方式因為將同一份資料存成一個大 JSON,在讀取時就會帶來很大的效能優勢。
空間局部性 (spatial locality): 資料在物理位置上很接近,一次取一塊資料時可以順便取到其他會用到的資料。
時間局部性 (temporal locality): 資料會在短時間內重複使用,cache 命中率高。
資料模型就像系統的骨架,常常決定我們怎麼思考資料問題、以及寫的程式會長什麼樣子,它可能影響到程式可讀性和可維護性、query 難度與效能、schema 改動彈性等等。此外,一個模型其實可以用另一個模型模擬出來,比如關聯式資料庫也可以呈現 graph 資料,只是比較笨拙一點。其他資料模型還有全文檢索 (full-text search)、序列相似性搜尋 (sequence-similarity search)、欄式資料模型 (column-family) 等,不同模型有各自擅長的領域和場景,我們依應用程式核心業務邏輯的不同而選擇不同系統、或是混合著使用。
下一篇來看資料模型具體是如何實現的,也就是儲存引擎的工作原理:以資料庫的角度來看要怎麼儲存與檢索資料。
Reply by Email