
Dataflow#
資料可以透過多種方式從一個 process 流向另一個 process,常見的流動方式有:透過資料庫、透過服務呼叫、透過非同步訊息傳遞。
透過資料庫的 dataflow#
一個 process 寫入 encoded data,另一個 process 之後讀取它。
在 DB 裡,會有 process 來存取資料,有的 process 將資料編碼並寫入 DB,有的從 DB 讀取資料並解碼,有時讀寫都在同一個 process 中。這些 process 可能是各種應用程式或服務,也可能是同一個服務的多個 instance(為了可擴展性或容錯而並行運行)。
透過服務的 dataflow:REST and RPC#
一個 process (client) 透過網路向另一個 process (server) 發送請求並期望盡快得到回應。
當 process 需要透過網路來溝通,常見的方式是準備 client 和 server 兩個角色,server 在網路上開放 API(server 開放的 API 也稱為 服務 (service)),client 可以向 API 發出請求,來下載或提交資料。
在允許客戶端查詢和提交資料這方面,服務和 DB 蠻相似的,但最上層的 API 服務通常是 application-specific,client 和 server 必須在 API 的細節上達成共識。對於 API 的 input 和 output 會依應用程式和業務邏輯預先定義好,服務也可以更精細的控制 client 能做和不能做的事。
服務導向/微服務架構:概念是將大型應用程式按功能拆分成比較小的服務,當一個服務需要另一個服務的功能或資料,就對它發出請求,因此 server 本身也可以是另一個服務的 client。
這種設計的目標是藉由讓每個服務獨立部署和演化,使應用程式更容易維護和適應變化。
當使用 HTTP 作為服務的底層通訊協定(protocol)時,稱爲 web service。web service 有 REST 和 SOAP 兩種常見做法,其中 REST 是流行的設計哲學(而非協定),以 REST 風格來設計的 API 稱爲 RESTful API,它相當容易理解,在測試和 debug 上也很方便。
RPC(Remote Procedure Call)是另一種 API 設計模式,例如 gRPC 是使用 Protocol Buffers 編碼格式的 RPC 實作。它由 client 發出請求以執行某個動作,然後遠端 server 去執行那個動作,讓呼叫遠端網路服務就像呼叫 local function 一樣(RPC 使用的 protocol 不一定都是 HTTP,也可以跑在 TCP 或 UDP 上。)
web service 就是透過網路發出 API 請求的一系列技術體現,它不只用於網站,也會用在其他環境像是:
手機 APP 透過 HTTP 發送請求給服務、微服務架構中同個組織下的服務發送請求給另一個服務 (如 middleware)、一個服務發送請求給另一個組織的服務
(常見於不同組織間的後端系統進行資料交換,包括線上服務提供的 public API 如信用卡處理系統或共享 user data 的 OAuth)。
同樣用於資料傳遞的 "webhook" 與 API 最大的差異在於 "是誰主動", API 是 client 請求後發送,webhook 是由 server 推送。
許多不需要 client 主動查詢就有即時回報的設計,背後就是用 webhook 在各個系統間傳話,例如按下購買後立刻收到訂單成立簡訊、訂餐完自動跳出外送進度通知、匯率到價提醒。
它可以說是 event-driven 系統的主角,只要 event 發生 server 就會將資料即時送出,適合用在需要即時更新或自動同步的場景。
透過訊息傳遞的 dataflow#
一個 process (sender) 發送訊息到 message broker,broker 將訊息發送給另一個 process (recipient)。
client 的請求(通常稱為 message)透過 message broker (或稱 message queue)這個中介低延遲傳遞到另一個 process。跟 RPC 不同的地方在於,這種通訊通常是單向的,sender 不會期待 recipient 的回應, 而且 sender 不會等待訊息是否被確實傳遞給 recipient 處理,只是將訊息丟進 queue 然後就忘了它,這種通訊模式是非同步的(asynchronous)。
message broker 的用法是,一個 process 發送一個訊息到指定的 queue / topic,broker 會確保訊息被傳遞給一個或多個 consumer / subscriber。同一個 topic 可以有多個 producer 和 consumer。一個 topic 只能提供單向的 dataflow。message broker 作為中介節點會暫存訊息,相較於直接的 RPC,使用 broker 有幾個優點:
- 當接收者掛點時,broker 可以當作緩衝區,提高系統可靠性。
- broker 可以自動重發訊息給之前壞掉的接收者,防止訊息遺失。
- 一個訊息可以發給多個接收者。
- sender 不需要知道接收者的 IP 和 port,面對雲端部署中上上下下的虛擬機很好用。
- 將收送雙方做到邏輯上的解耦;sender 只負責發送訊息,不關心誰來消費。
在流式處理 (stream processing) 這種處理資料的方式中,一個 record 通常被稱為一個 “事件” (event),本質上都是一個小小的不可變的物件,代表某時間點發生的某件事,比如一個 log、一筆交易、一個點擊紀錄。
event 由生產者 (producer, publisher, sender) 產生一次,然後可能由多個消費者 (consumer, subscriber, recipient) 所處理。
向消費者推播新事件的常見方式是使用訊息傳遞系統 (messageing system),生產者發送一個包含 event 的訊息然後推送給消費者 (可以將訊息看作是傳送 event 的載體,一個技術上的傳輸單位)。
生產者可以用網路直接傳送訊息給消費者,比如股票市場的 UDP multicast、或前述 webhook 背後的想法都是。另一種方式就是用 message broker 作為中介來發送訊息,讓不同系統間非同步傳遞資料。
Encoding#
何時需要編碼和解碼#
程式通常會用到(至少)兩種不同的資料形式,一種是在記憶體中的資料結構(data structure),一種是自包含的位元組序列(sequence-of-bytes)。
- 在記憶體中,資料會以 object、list、array、hash table、tree 等結構保存。為了讓 CPU 可以有效率地存取和操作,這些資料結構往往已經做了最佳化,通常會用到 pointer。
指標 (pointer) 是一種特殊的變數,裡面存的是其他變數的記憶體位置,可以間接指向其他變數的位址,讓 CPU 快速處理。 - 當資料離開了應用程式自身記憶體(要傳送到另一個沒有共享記憶體的程序),像是要寫入 DB 或檔案、或要透過網路傳送時,就需要將資料結構
編碼成某種自包含(self-contained)的位元組(byte)序列再進行傳送,例如 JSON document。反之,當要從 DB 或檔案讀取資料、或從網路接收資料時,就需要將位元組資料解碼為 in-memory 資料結構。
應用程式需要在這兩種資料形式之間做轉換。從 in-memory 表示形式轉換為 byte sequence 的作法稱為 編碼(encoding, serialization, marshalling),相反的過程稱為 解碼(decoding, parsing, deserialization, unmarshalling)。
這邊討論的編碼是指資料序列化,serialization 可能是更常用的術語。
它與字元編碼 (character encoding) (如 UTF-8、ASCII、Big5) 處理的層面不同,資料序列化決定資料的格式規範後,字元編碼負責將人類語言翻譯成電腦語言,把資料中的字元轉換電腦能理解的二進位數字。
例如: 我們將記憶體中的變數 {"msg": "你好"} 序列化存成 JSON,UTF-8 再將這 13 個字元編碼成 17 個 bytes,最後這些 bytes 才被存入硬碟或用網路傳輸。
Thrift, Protocol Buffers 等本身已經用二進位格式將資料序列化,不再依賴外部字元編碼。
編碼方式#
文本格式(textual format)的編碼有 JSON、XML、CSV 等,具有一定的可讀性(human-readable)。二進位編碼(binary encoding)如 BSON(JSON 的二進位編碼)、Thrift、Protocol Buffers、Avro 等,比文本格式更節省空間,但只有在解碼後才有可讀性。
範例資料(JSON document):
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
用 Protocol Buffers 編碼後如下(Protocol Buffers 對資料的編碼需要配合 schema):

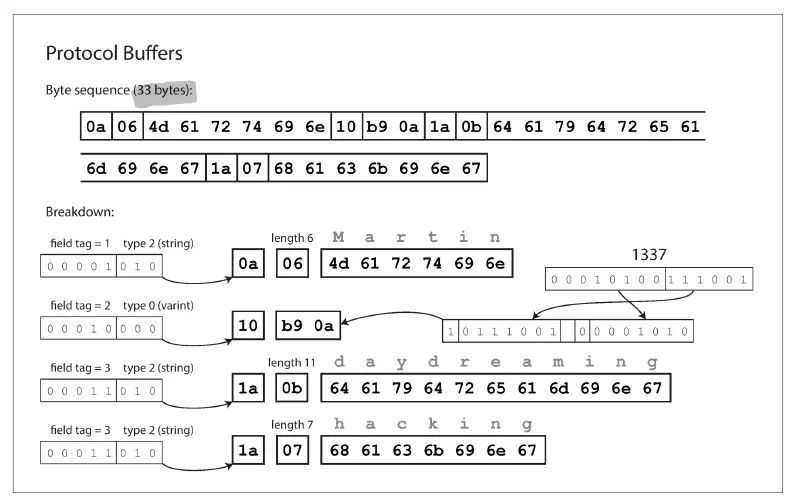
編碼在 dataflow 的重要性#
- Via database:寫入資料的程式對資料做編碼,讀取資料的程式對資料做解碼。
- Via service call (REST & RPC):client 將請求做編碼,server 將請求做解碼、並將回應做編碼,client 最終再將回應做解碼。
- Via asynchronous message passing:sender 將訊息做編碼,recipient 將訊息做解碼。
使用 DB 時比較少感受到編碼的存在,因爲無論用 SQL 或程式 insert,通常只需要提供原始資料,DB 供應商的驅動程式就會依網路協定做好編碼和解碼。(當然也可以手動做編碼,像是把整串 JSON {"name": "bear", "age": 5} 塞進 Oracle,但 Oracle 不會認識 bear 和 5。)而在 API 服務裡,RESTful API 最常用 JSON,gRPC 則是使用 Protocol Buffers。使用二進位編碼格式來自訂 RPC 協定,效能會比 REST 搭配 JSON 還要更好。message broker 作為 server 運行,就像是針對處理 message stream 而最佳化的 DB,通常沒有規定必須得用哪種 data model,由於訊息只是帶有 metadata 的位元組序列而已,所以可以使用任何編碼格式,比如生產者可以發送一個 JSON 訊息到 message broker。
stream processing 中的 event 可以用各種方式編碼 (文本字串、JSON、二進位格式等)。你可以將它編碼後,存成檔案或 insert 到 DB,或通過網路發送到另一個節點,或用訊息傳送到 message broker,如同文中提到的各種 dataflow 方式。
可演化性#
隨著新產品推出、user 需求改變、業務環境變化時,系統也需要跟著增加或修改功能。通常更改 APP 的功能都會伴隨著資料儲存的修改,比如需要增加新欄位、新的資料型態、或用新的方式呈現既有資料。當 schema 或資料格式改了,server 端的應用程式可能會用 rolling update 來分階段部署,至於客戶端的應用程式,由他們自己決定要不要更新。這代表新舊版的程式及資料格式會全部同時存在系統中,為了讓系統能持續穩定運行,我們需要保持系統前後的相容性:
- 回溯相容(backward compatibility):新程式可以讀取舊程式寫入的資料。
- 向前相容(foward compatibility):舊程式可以讀取新程式寫入的資料。
滾動升級 (rolling update):先將新版部署到少數幾個節點,接著檢查它是否正常運行,然後再逐步完成所有節點的部署。這樣服務不用停機就能部署新版,更有利於頻繁發佈、快速演化。
也就是說,在 rolling update 期間,我們需要假設不同節點上正跑著不同版本的應用程式碼,所以在系統內流動的所有資料的編碼方式,都要能做到回溯相容(新程式讀舊資料)和向前相容(舊程式讀新資料)。以 API 服務為例,server 和 client 用的資料編碼必須在不同版本的服務間彼此相容,新舊版本的兩端才能同時運行,每個服務也才能經常發佈新版本。 這樣系統的不同部分可以獨立升級,不用等到所有變更一次到位,對於可演化性、以及應用程式的易變性都很有幫助。
Reply by Email