
當資料的儲存與檢索涉及到多台機器,會怎麼樣?
分散式資料系統的目的#
考慮將一個資料庫跨多台機器分佈,可能有幾種原因:
容錯性和高可用性 (Fault tolerance / high availibility)
即使系統有某部份失效(比如一台或多台機器或整個 datacenter 故障),系統還是能保持正常運行,進而提升可用性。
可擴展性 (Scalability)
本篇關注的是無共享架構,也就是水平擴展,藉由增加可提供讀取 query 的機器數量,來提高讀取吞吐量。
🖌️ 要擴展系統來支撐更高的負載,有幾種方式,包括 垂直擴展 (共享記憶體架構)、共享磁碟 (共享磁碟架構)、水平擴展 (無共享架構):
- 垂直擴展 / shared-memory architecture:一個作業系統下由許多 CPU、RAM 和磁碟所支撐,CPU 可以任意存取連接在系統上的記憶體和磁碟;一台機器是由系統內所有元件共同合作而形成的。這種方式的問題在於成本增長速度,將所有資源升級成兩倍的機器,成本通常超過單台的兩倍,也不一定能處理兩倍的負載,而且可提供的容錯能力也有限。
- 共享磁碟架構 / shared-disk architecture:多台伺服器之間共享磁碟。每台伺服器有自己獨立的 CPU 和 RAM,但將資料儲存在共享的磁碟陣列上,這些磁碟陣列和伺服器之間大多以高速網路來連接。這種架構常見於一些資料倉儲,比如 NAS (Network Attached Storage),但是鎖的競爭會限制到可擴展性。
- 水平擴展 /
shared-nothing architecture:每台機器或虛擬機稱為一個節點(node),每個節點獨立使用自己的 CPU、RAM 和磁碟,節點之間的協調大多在軟體層次上透過網路完成。
延遲 (Latency)
讓資料在地理位置上靠近 user 以減少存取延遲。使 user 與資料互動的速度越快越好,不用繞半圈地球去拿資料。
並不是所有 use case 都適合無共享架構,儘管它有很多優點,但通常會增加應用程式的複雜度(比如需要處理過時/衝突資料、冪等性控制),有時還會讓 data model 的表達性出現侷限(比如 join 的限制、index 的高維護成本)。想把資料分散在多個節點,應用程式開發人員要謹慎考慮這種分散式系統會出現的限制與 trade-off。
常見的資料分散機制#
將資料分散在多個節點,有兩種常見方式:
複製副本 (Replication)
在多個不同節點上保存相同資料的副本 (a copy of the same data)。每一個儲存 dataset copy 的節點稱為一個 replica。Replication 可以提供 redundancy,也有助於提升效能。
分區 (Partitioning) / 分片 (Sharding)
將大型資料庫拆成多個小子集,這些子集稱為 partition (shard),不同的 partition 可以被分配到不同節點。
在 replication 方面,當 dataset 夠小,可以假設每台機器都有足夠空間來保存完整的 dataset copy。當 dataset 大到無法由單台機器儲存時,就可以將 dataset 做 partitioning。兩種機制也經常混合使用,例如將一個資料庫拆成兩個 partition,每個 partition 內有兩份 replica。(Partitioning 通常會跟 Replication 結合運用,這樣每個 partition 的 copy 就可以儲存在多個節點上。)
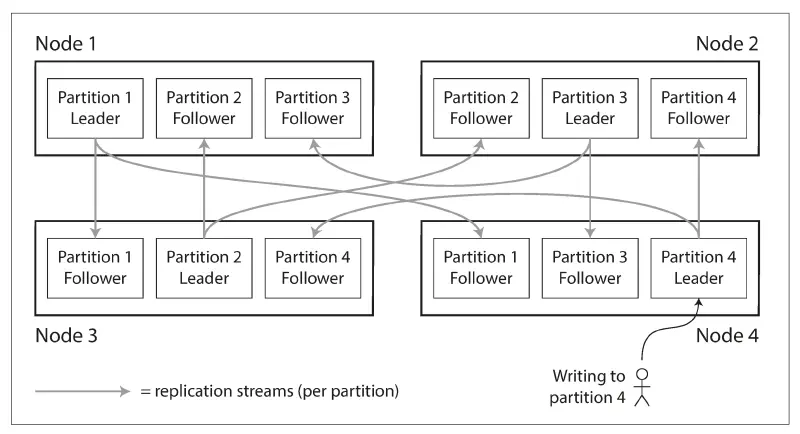
Replication#
資料隨時都在變化,replication 困難的地方就在於如何處理這些會變的 replicated data。每次對 DB 寫入,每個 replica 也必須隨之處理,並確保所有 replica 的資料是一樣的。有幾種演算法可以在節點之間複製變動資料,包括 單領導複製 (single-leader replication)、多領導複製 (multi-leader replication)、無領導複製 (leaderless replication),幾乎所有分散式資料庫都採用了其中一種方法。
leader-based replication 的原理是:指定一個 replica 作為 leader (主節點, primary, master),其他的 replica 作為 follower (從節點, read replica, secondary, slave)。當客戶端要寫入 DB 時,必須發請求給 leader,leader 會先將新的資料寫入它的本機儲存。同時,leader 也會發送資料變更 (作為 replication log / change stream 的一部分) 給所有 follower,每個 follower 拿到 log 再去更新自己的本機資料。
leader-based replication 要求所有的寫入操作都必須經過主節點 leader,而讀取查詢可以交給任何 replica 處理。換句話說,當客戶端想讀取資料,他可以 query leader 或 follower,但寫入只能選 leader;而 follower 對客戶端來說是 read-only。此外,leader-based replication 不限於 DB 使用,分散式 message broker (如 Kafka) 也有用到。
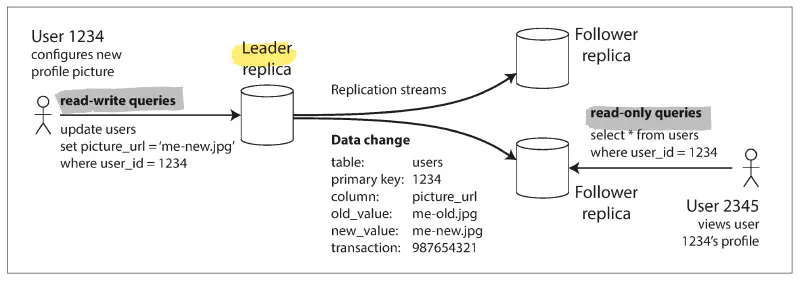
- single-leader: 是最流行的方法。client 將所有寫入請求都發到單一節點 (leader),由 leader 向其他 follower 發送資料變更的事件流。每個 replica 都可以提供讀取,但從 follower 讀到的資料可能會是舊值。
- multi-leader: client 將寫入操作發到多個 leader 的其中一個,任一個 leader 都可以接受寫入請求。leader 向彼此、以及向 follower 發送資料變更的事件流。
- leaderless: client 將寫入請求發送到多個節點,要讀取資料時,則將請求平行發給多個節點,從不同節點取得回應並檢測、糾正節點上的舊資料。
replication 的設計上還要考慮許多重要細節,像是要用同步複製還是非同步複製?(當出現故障時這會對系統行為有很大影響) 當節點停機、故障或維護時,如何處理失效的 replica?當網路中斷時,如何讓應用程式離線操作?
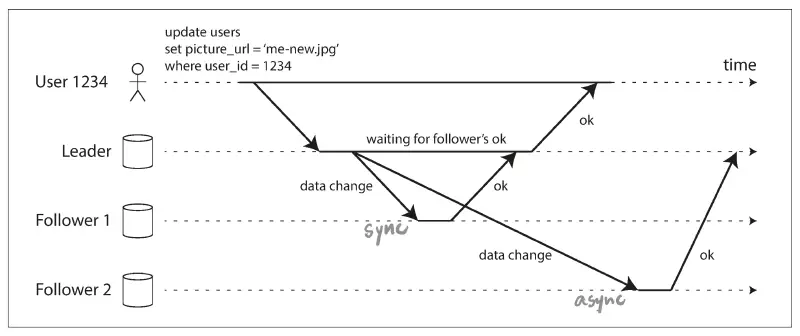
從一個寫入發生在 leader、到反映在 follower 之間的 delay,稱為複製落後 (replication lag)。如果應用程式從非同步 follower 讀取資料,結果 follower 其實落後了,那它看到的可能就是舊資料。DB 裡不一致的問題就會出現:同時對 leader 和 follower 跑相同的 query 可能得到不一樣的資料。這種不一致是暫時的,只要停止寫入 DB 然後等一陣子,follower 最終會趕上來和 leader 保持一致,這種現象稱為最終一致性 (eventual consistency)。更好的描述可能是收斂 (convergence),我們希望所有 replica 最終都收斂到相同的值。
在系統平穩運行時,非同步複製的速度很快,lag 也許只有幾分之一秒。但如果系統運行在容量邊緣或是網路出問題,lag 可能就是幾秒甚至幾分鐘。落後時間太久導致資料不一致,可能會帶給 user 糟糕的體驗,比如明明 insert 了卻 select 不到資料、或是感覺時光倒流等等。對於複製落後可能造成的奇怪現象,有些一致性模型可以幫助應用程式做出正確行為,例如 read-after-write consistency (也稱為 read-your-write 讀己所寫)、monotonic read (單調讀取)、consistent prefix read (一致性前綴讀取)。雖然應用程式可以使用這些機制,來提供比底層 DB 還要更強的一致性保證,但這些問題在 application code 中處理起來往往很複雜又容易出錯。這也正是「交易」(transaction) 存在的原因,它是 DB 提供更強保證的一種方式,讓應用程式開發者可以相信 DB 而不用擔心複製問題,從而簡化了 application code。關於交易,之後的篇章說明。