
資料要怎麼存才能在不同 workload 下達到理想的讀寫效能?
資料模型是應用程式開發者提供給資料庫的資料格式,不同模型對應到的資料庫會實作不同的儲存引擎 (storage engine),而儲存引擎是資料庫的底層軟體組件,它是在磁碟與記憶體中實際管理數據的角色,決定資料如何 寫入 磁碟以及如何 讀取。
由於我們很難要求一個資料庫同時將讀寫都做到最好,因此應該根據應用程式的 workload 去選擇最合適的儲存方式。這裡的 workload 指的是系統的存取模式、讀寫行為特徵,也就是應用程式使用資料庫的習慣,具體來說可能包含:讀多還是寫多?資料大小與成長速度?(每秒新增幾千筆?) 批次或流式處理需求?(批次分析或寫入像串流?) 延遲可容忍度等等,這些因素影響到我們如何挑選和調校儲存結構。
磁碟 (disk) 是用磁性或光技術儲存和檢索資料的儲存設備,例如: HDD、SSD。
磁碟 I/O 是指從磁碟讀取和寫入的過程。當程式或 OS 需要存取磁碟上的資料,就會執行磁碟 I/O 操作。
資料在傳輸時,系統會先把磁碟裡的資料大批搬到記憶體待命,接著 CPU 再從記憶體裡極速抓取資料來運算。
磁碟 ➔ 記憶體:會受限於磁碟頻寬,也就是磁碟可以傳送資料到 RAM 的速度,這會影響到載入時間,像是啟動電腦、開啟遊戲、打開大型檔案時,資料必須先從磁碟搬到 RAM,CPU 才能處理。
記憶體 ➔ CPU:會受限於記憶體頻寬,也就是資料從 RAM 進入 CPU 快取的速度,這會影響到運算能力,比如影像渲染、AI 模型推理、科學計算。
Transaction processing or Analytics?#
依使用資料庫的模式不同,可以簡單分為 線上交易處理 (OLTP) 和 線上分析處理 (OLAP) 兩種存取模式。有時兩者之間的區別沒有很明顯,但還是可以列出它們的典型特徵如下:
| 交易處理系統 OLTP | 分析系統 OLAP | |
|---|---|---|
| 主要使用者 | end user / 客戶,透過 web 應用程式 | 內部分析人員,用來支援決策 |
| 主要讀取模式 | 每次查詢少量記錄,根據 key 取得原始資料 | 聚合了大量記錄,計算與匯總統計資訊 (count, sum, avg 等) |
| 主要寫入模式 | random-access,從 user input 到寫入 DB 的延遲較低 | 大量匯入 (ETL) 或 event stream |
| 資料意涵 | 資料的最新狀態 (當前時刻) | 過往發生的事件歷史 |
| dataset 大小 | GB~TB | TB~PB |
Storage engines optimized for OLTP and OLAP#
因此概括來說,儲存引擎可以分為兩大類:針對 OLTP 進行最佳化的架構,以及針對 OLAP 進行最佳化的架構。
OLTP#
OLTP 系統通常是面向 end user 的,代表它們可能會遇到大量的請求。通常 APP 在每次的 query 只會處理少量資料,APP 用 key 來請求資料,而儲存引擎用 index 來加速查找所請求的資料。常見的場景像是銀行轉帳、電商下單、更改密碼 (想找 “ID=100” 的人)。在這裡會遇到的瓶頸通常是 disk 的搜尋時間。
索引 (index) 是從原始資料衍生出的一種附加資料結構,使查找 DB 中某個 key 的 value 能更有效率,例如:B-tree、Hash index。
它背後的基本思想是保留一些 metadata 作為指引來幫助我們定位資料。儲存引擎會根據其設計目標來選擇主索引結構。
index 影響的層面只有查詢,它沒有辦法用來加速寫入。增加或刪除 index 不會影響 DB 內容,只會影響查詢效能。
在寫入方面,最簡單的寫入操作就是直接追加內容到檔尾 (log),這種效能很難被超越。任何 index 都會讓寫入速度變慢,因為每次寫入資料都需要更新 index。
對於儲存系統來說這是很重要的 trade-off,精心挑選的 index 能加快查詢速度,但它又會減慢寫入速度。
因此通常需要 APP 開發者或 DBA,根據 APP 的典型查詢模式去手動建立 index。
在 OLTP 方面,有 分頁導向 和 日誌結構 兩種流派的儲存引擎:
分頁導向派 (page-oriented)-直接更新頁面:
它將磁碟視為一組固定大小、可被覆寫的 page,直接修改磁碟上的 page,屬於原地更新派 (update-in-place)。B-tree是這一哲學的最大代表,在主要的關聯式資料庫、和許多非關聯式資料庫都有被使用。日誌結構派 (log-structured)-以追加記錄為核心:
只允許追加內容到檔案、和刪除過時的檔案,已經寫入的檔案不會被修改。這一派屬於比較新的發展,它們有系統地將磁碟的隨機寫入轉變為循序寫入,來實現更高的寫入吞吐量。LSM-tree、SSTables、Lucene、Cassandra、HBase、BitCask 等皆屬於這一類。B-tree 將資料庫分解成固定大小的區塊 (block) 或分頁 (page),通常是 4 KB 或更大,每次讀取或寫入都是以 page 為單位。 日誌結構索引將資料庫分割為大小可變的 segments,通常是幾 MB 或更大一些,並且對 segment 的寫入操作是循序的。
B-tree vs LSM-tree#
無論哪種 data model,底層的儲存引擎通常圍繞著 B-tree 家族和 LSM-tree 運作。根據經驗,B-tree 通常讀得更快,而 LSM-tree 寫得更快。詳細內容另寫一篇…🌴
| B-tree | LSM-tree | |
|---|---|---|
| 主要應用 | 大多數 RDBMS | 分散式與高寫入資料庫 |
| 讀取性能 | 極佳 (固定層級,搜尋路徑短) | 較慢 (需要檢查多個層級與布隆過濾器) |
| 寫入性能 | 較慢 (需要隨機 I/O 更新磁碟頁面) | 極快 (僅追加日誌,順序寫入) |
| 適用場景 | 頻繁讀取和更新的傳統應用 | 海量數據與寫入極頻繁的系統 |
LSM-tree 被認為寫入能力強,是因為它運用批次和轉換的方式,先在記憶體中累積一堆資料,再一次性有順序地寫入磁碟,讓單位時間內能處理的總資料量變大 (高吞吐),並不是讓單次寫入的邏輯變簡單。如果是開發一個需要每秒處理十萬筆 log 的系統,這會相當有利。
OLAP#
OLAP 系統或資料倉儲 (Data warehouse) 的主要使用者是業務分析人員,它處理的查詢量通常遠比 OLTP 系統要低,但每個查詢往往很嚴苛,需要在短時間內掃描數百萬筆資料,比如計算過去一年的總營收、分析上期促銷活動期間比平時多賣了幾根香蕉。而對於這種 workload,disk 頻寬常會是瓶頸所在。當你的查詢需要在大量的列中進行掃描,有沒有用 index 也許相對不是那麼重要,重要的是如何緊湊的編碼資料,來降低需要從磁碟讀取的資料量。行式儲存 (column-oriented storage) 是越來越流行的解決方案,它按行緊湊的編碼和壓縮資料,減少了磁碟 I/O,並有助於 CPU 週期的高效利用。
Data warehouse#
公司裡可能會有數十個不同的 OLTP 系統,像是電商網站、庫存追蹤、供應商系統、客服系統等等,由於 OLTP 應該專注於處理交易,因此分析查詢用的 OLAP,需要透過 ETL 將不同 OLTP 系統的資料 (唯獨副本) 匯集到資料倉儲。用分隔的資料倉儲進行分析 (而不是直接查詢 OLTP 系統),主要的好處在於不會影響到 OLTP 系統的交易效能,此外,可以設計對分析友善的 schema,或針對分析的存取模式進行最佳化 (比如行式儲存) 和 index 演算法優化。
ETL (Extract-Transform-Load):第一步從 OLTP 資料庫擷取 (Extract) 資料,第二步是轉換 (Transform) 成便於分析的 schema 及資料清理,最後一步是載入 (Load) 至資料倉儲中。
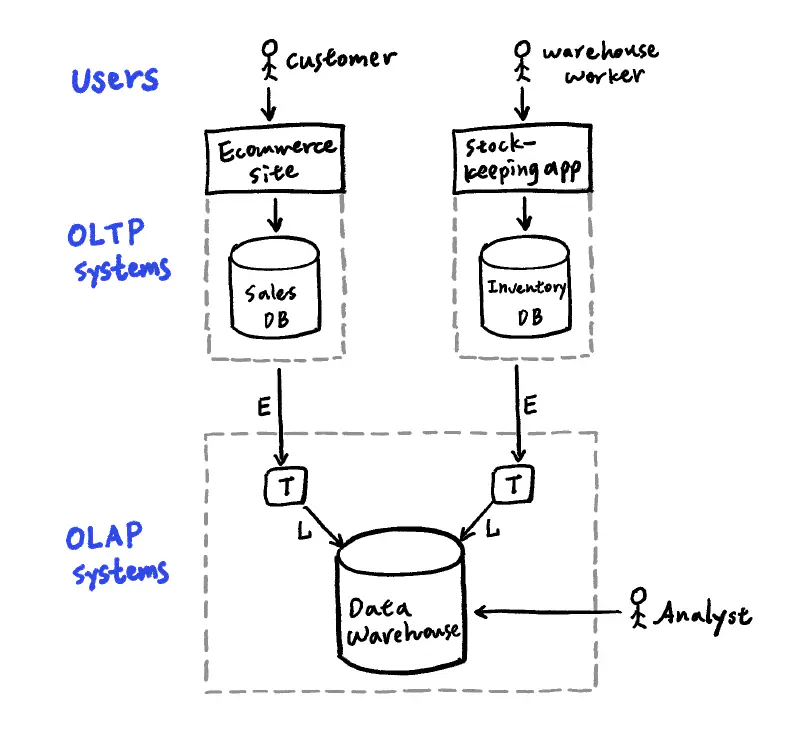
Schema for analytics#
在分析領域,relational model 是資料倉儲最常見的資料模型,因為 SQL 通常適合分析查詢。許多資料倉儲都使用 star schema(也稱為維度模型 dimensional modeling):它以 fact table 為中心,每一列代表在特定時間發生的事件;並以 foreign key 來參照到其他 dimension table,通常代表事件的 who, what, where, when, how 和 why。舉例來說,主要的資料表 fact table 可能是銷售資料表,每一列表示客戶買了一項產品,而連出去的 dimension table 有客戶表、商品表、商家表、日期表、促銷檔期表。當 table 關係被視覺化時,fact table 在中間並被維度表包圍,這些 table 連起來的形狀就像星星光芒。
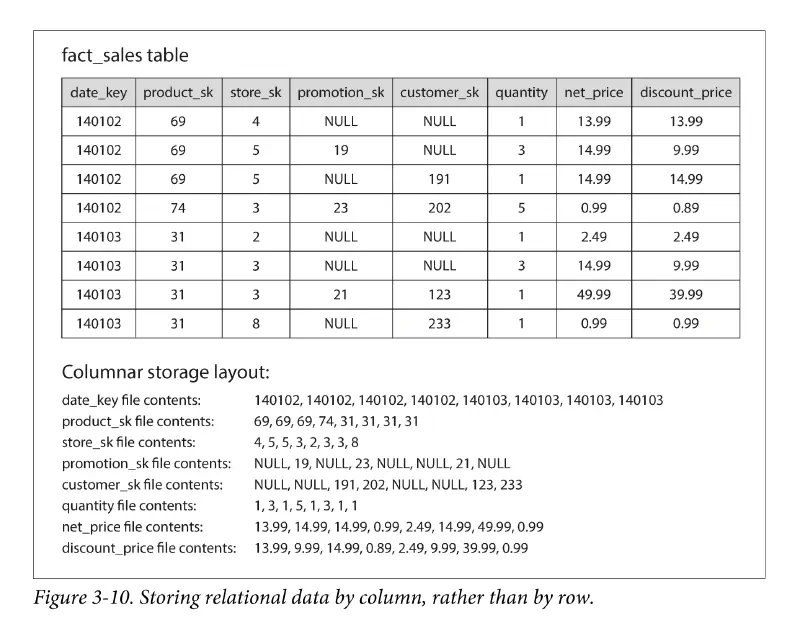
fact table 可能是 PB 級資料量,有數兆個列和一兩百行寬,但資料倉儲的典型查詢,通常只會查幾個欄位 (很少會 select *),因此有了行式儲存的做法,按 column 而不是按 row 來儲存資料,它在關聯式與非關聯式資料庫都可以用。由於它將每行的資料存在一個單獨檔案中,查詢時只需要讀取和解析該查詢有用到的那些行,因此可以節省大量的磁碟 I/O。
Bitmap index#
在 OLAP 系統下,我們經常需要對數十億筆資料進行複雜的篩選,例如尋找「性別=女 and 地區=紐約 and 會員=金卡」的族群,對於這樣大規模的查詢,點陣圖索引 (bitmap index) 是一種常用的索引,它適合用在 低基數 (low-cardinality) 的欄位,也就是 distinct value 比較少、重複值很多的欄位,像是性別、城市、支付狀態。bitmap 的運作原理是用一個位元 (bit) 來代表一列 (row) 數據,1 代表符合條件,0 代表不符合。這種設計除了能做到極高的壓縮率,大幅節省儲存空間,在處理多個條件過濾時的速度也很快。由於 CPU 可以直接對 bitmap 執行底層的 AND、OR、NOT 位元運算,這種硬體層級的操作速度非常快,可以在毫秒內完成多條件組合的複雜 query。bitmap index 的結構也與前面提到的行式儲存的概念互相契合,兩者都是按 column 存放的邏輯,DB 在執行篩選查詢時,可以直接抓取特定欄位來運算,不必掃描無關資料。

不過,bitmap index 只適用在唯讀或極少更新的資料倉儲環境,不要將它建在頻繁交易的 OLTP 表上,只要併發寫入一高,系統就容易因為 locking contention 而癱瘓。而且索引的更新成本高,頻繁的更新導致不斷解壓縮、修改位元再重新壓縮,會消耗 CPU 並使索引體積膨脹。
為了節省空間,物理上 DB 會切多個 bitmap segments 來儲存資料,每個 segment 包含一個起始 rowID 和結束 rowID,數百數千 row 的 bitmap 資訊被壓縮並存在磁碟上同一塊 block。
當一個 user update 第 10 列,DB 會鎖定整個 bitmap segment,若同時有另一個 user 想 update 第 30 列,但那一列剛好在同一個 segment,他就必須等待,這種現象稱為鎖定衝突或鎖競爭。
Keep everything in memory?#
不同索引解決的問題面向不同,但本質上都是為了應對磁碟的限制 (比如減少跳轉次數、節省磁碟 I/O)。想獲得良好的讀寫性能,就必須仔細安排磁碟上的資料佈局。當 RAM 變的更便宜,加上許多 dataset 其實沒有那麼大,將資料完全保留在記憶體是可行的,甚至能分散到多台機器上,一些 in-memory database 的主要用途是作為快取 (cache)。與直覺相反,in-memory DB 的性能優勢,並非來自它們不需要從磁碟讀取資料。由於 OS 會將最近用到的 disk block 快取在記憶體當中,所以如果記憶體充足,即使是 disk-based 儲存引擎也可能永遠不需要從磁碟讀資料。in-memory DB 得以更快,是因為它們不需要將 in-memory 資料結構編碼 (encode) 成可以寫入磁碟的格式,省去了這一段造成的開銷。關於編碼,下一篇說明。
Reply by Email